Google released DiffusionGemma, an experimental open-source text generation model with 26 billion parameters, on June 10, 2026 [1, 2]. The model uses a Mixture of Experts architecture and achieves speeds up to four times faster than traditional autoregressive models by generating 256 tokens in parallel via diffusion instead of sequential token-by-token methods [3, 4, 1, 5, 2].
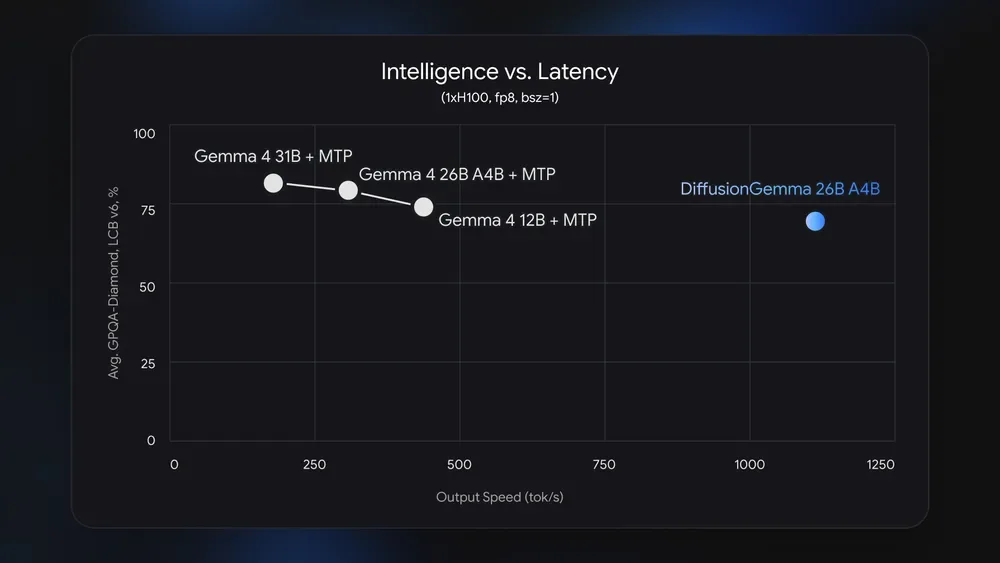
DiffusionGemma activates only about 3.8 billion parameters during inference, fitting within approximately 18GB of GPU VRAM after quantization [3, 4, 5, 2]. On an Nvidia H100 GPU, it can generate over 1,000 tokens per second and over 700 tokens per second on an Nvidia GeForce RTX 5090 [3, 4, 5, 2]. The model uses bi-directional attention, allowing each token to attend to all other tokens in the generated block, which benefits non-linear applications such as code infilling, inline editing, mathematical graphs, and amino acid sequence generation [3, 4, 5, 2].
The model iteratively self-corrects output by refining the entire text block with each forward pass [3, 4, 5, 2]. However, Google positions DiffusionGemma mainly as an experimental tool for researchers and developers prioritizing speed in local interactive workflows rather than production-quality output [3, 1, 2]. The output quality is lower than standard autoregressive Gemma 4 models; "For applications that demand maximum quality, we recommend deploying standard Gemma 4," Google said [5].
The speed advantage mainly applies to low to medium concurrency local inference on dedicated GPUs; gains diminish in high concurrency cloud deployments [1, 2]. DiffusionGemma is released under the Apache 2.0 open-source license and is available on HuggingFace, compatible with local inference tools like llama.cpp [3, 5].
Google officially released DiffusionGemma on June 10. The company targets it at developers and researchers needing fast, local text generation rather than production-grade text solutions [1, 2].