谷歌于2026年6月10日发布了实验性质的开源文本扩散模型DiffusionGemma。该模型采用了26亿参数的专家混合(Mixture of Experts,MoE)架构,且基于Apache 2.0协议开源 [1, 2, 3, 4]。
与传统的逐词生成(自回归)模型不同,DiffusionGemma能够并行生成最多256个词的文本块,每次输出一个完整文本块,显著提升生成速度。谷歌指出,该模型在推理阶段仅激活约3.8亿参数,便可运行于拥有18GB显存的GPU上,兼顾了效率与硬件需求 [1, 2, 4]。
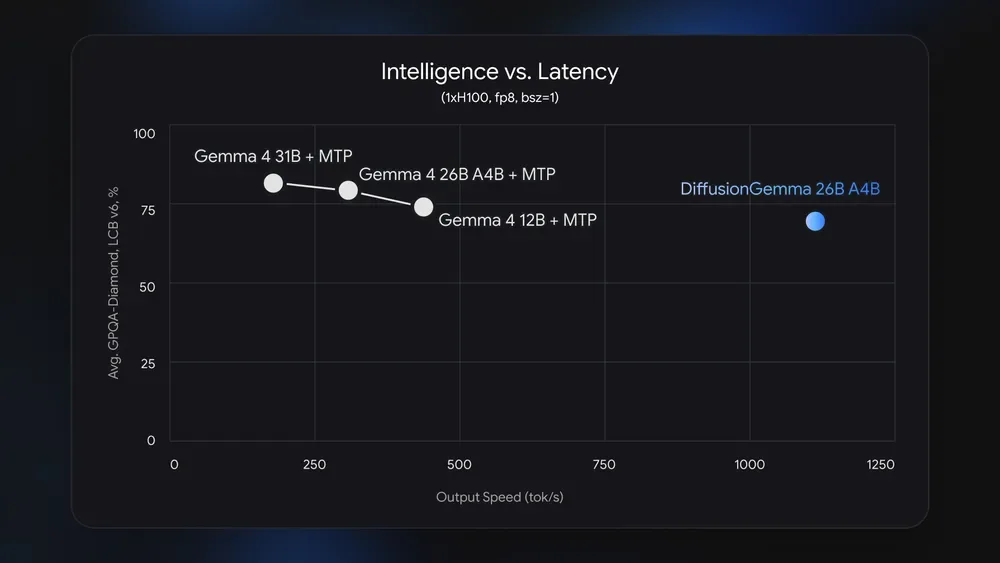
性能测试显示,DiffusionGemma在Nvidia GeForce RTX 5090显卡上每秒可生成超过700个词元,在性能更强的Nvidia H100显卡上更突破1000词元每秒,生成速度较传统Gemma 4自回归模型提升约4倍 [1, 2, 4]。
此外,DiffusionGemma使用并行双向注意力机制,使得每个词元都能关注同块内所有其他词元,适合于非线性任务,例如代码补全、分子结构和氨基酸序列预测,以及数学图形生成,表现更佳。模型还通过迭代自我纠正输出文本,实现生成过程的实时改进 [1, 2, 4]。
谷歌提醒,DiffusionGemma目前尚属实验模型,整体输出质量略逊于标准的Gemma 4自回归模型。因此在需要最高质量文本输出的生产环境中,推荐继续采用Gemma 4模型 [1, 3, 4]。
值得注意的是,该模型的加速优势在本地推理和低并发场景中最明显,在云端的高并发部署中提升有限 [3]。DiffusionGemma已在HuggingFace平台上线,并针对包括GeForce RTX 5090、4090及DGX等Nvidia硬件进行优化 [4]。