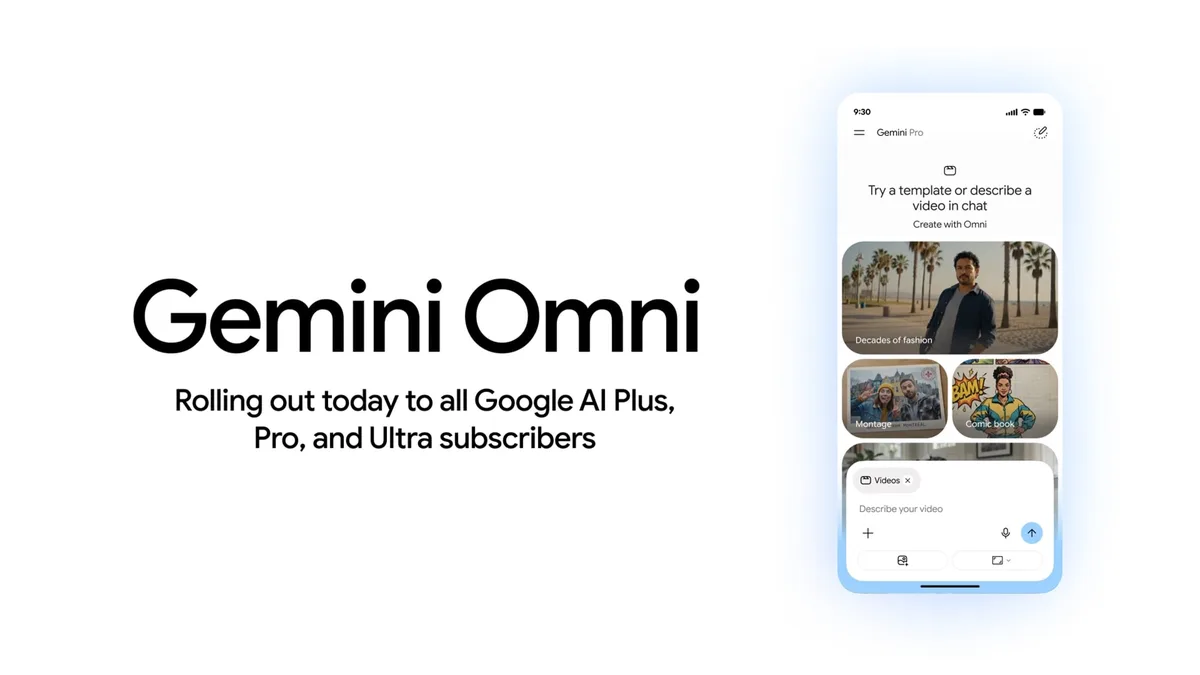
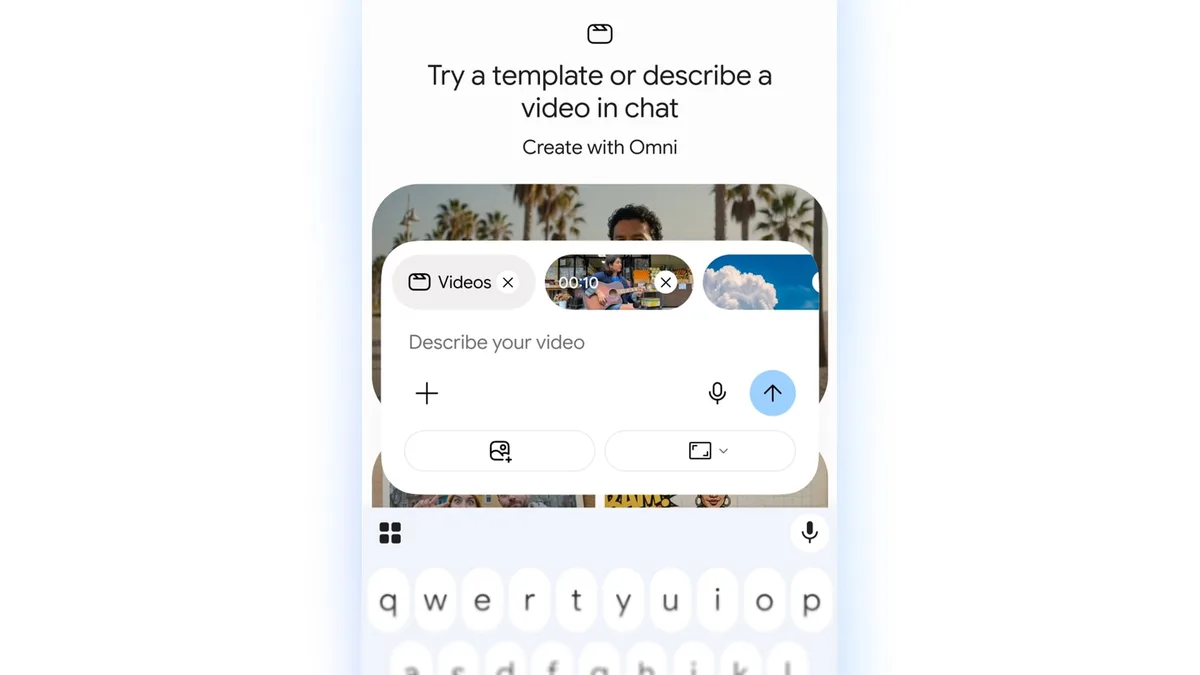
Google revealed Gemini Omni on May 19 at its Google I/O 2026 developer conference as a new multimodal AI model that can generate and edit videos from combined inputs of text, images, audio, and video [1, 2, 3, 4]. The company said users can "create anything from any input," highlighting its ability to reshape video content through natural language commands [1].
Gemini Omni supports step-by-step video editing via natural language conversation. Users can alter characters, environments, camera angles, style, and specific details while maintaining consistency across multiple edits [5, 1, 2, 3]. Google says the model understands concepts from physics, history, science, and culture to improve realism and storytelling in generated videos [5, 1, 2, 3]. The AI accounts for physical forces like gravity and fluid dynamics to create more believable outputs [2, 3].
An initial rollout called Gemini Omni Flash is available through the Gemini app, Google Flow, and YouTube Shorts. The platform allows users to remix others’ YouTube Shorts by restyling clips, inserting themselves, or changing content using prompts [1, 6, 3]. Videos created or modified with Gemini Omni on YouTube Shorts carry a digital watermark and a link back to original videos to prevent misuse [6, 3].
Gemini Omni can also make digital avatars that resemble and sound like the user, enabling personalized video generation and editing [1, 3]. Google emphasized Gemini Omni is a major step beyond its earlier Veo video model. Nicole Brichtova, Google DeepMind's product management director, called it "the next step towards the progression of combining the intelligence of Gemini with the rendering capabilities of our media models" [1].
Alongside Gemini Omni, Google updated its broader Gemini ecosystem. This includes Gemini 3.5 Flash, Google AI Studio, and developer tools designed to simplify integration of generative media features [4]. The model’s ability to mix AI intelligence with media rendering sets it apart from previous offerings [1, 3].
Google CEO Sundar Pichai described Gemini Omni as a way to "create anything from any input," reflecting the system’s versatility in video creation [1]. The company stated users can "edit the action, add in new characters or objects, or transform a moment into something unexpected. Change the environment, angle, style or even specific details" using natural language prompts [3].