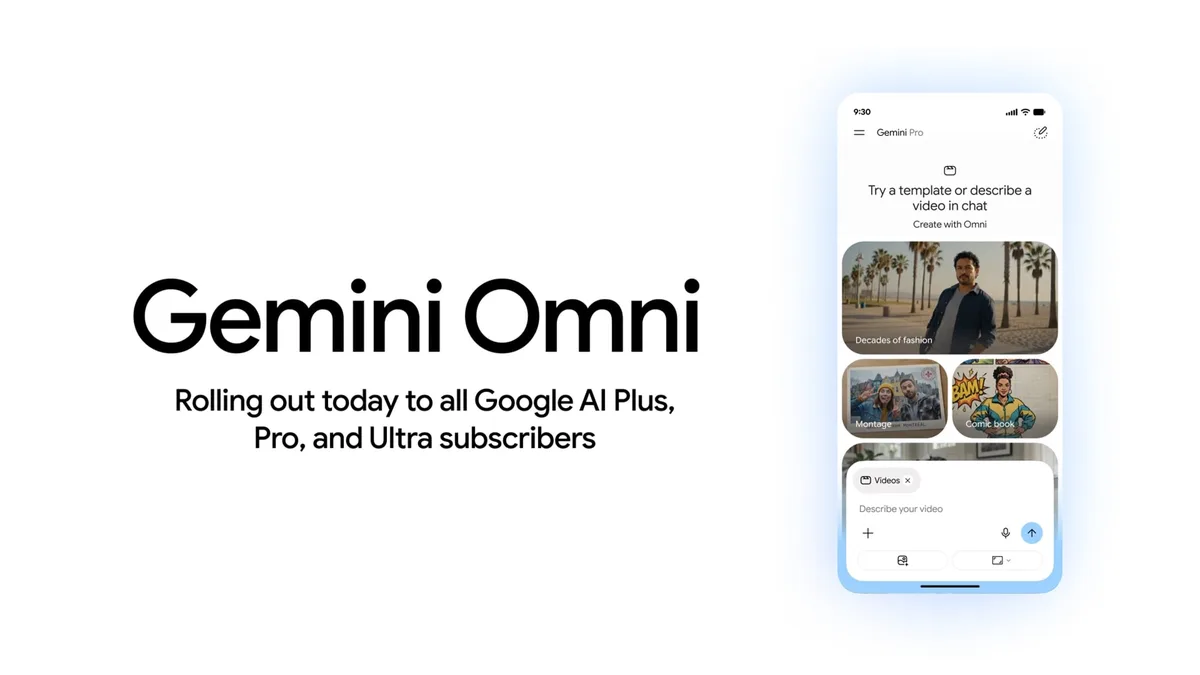
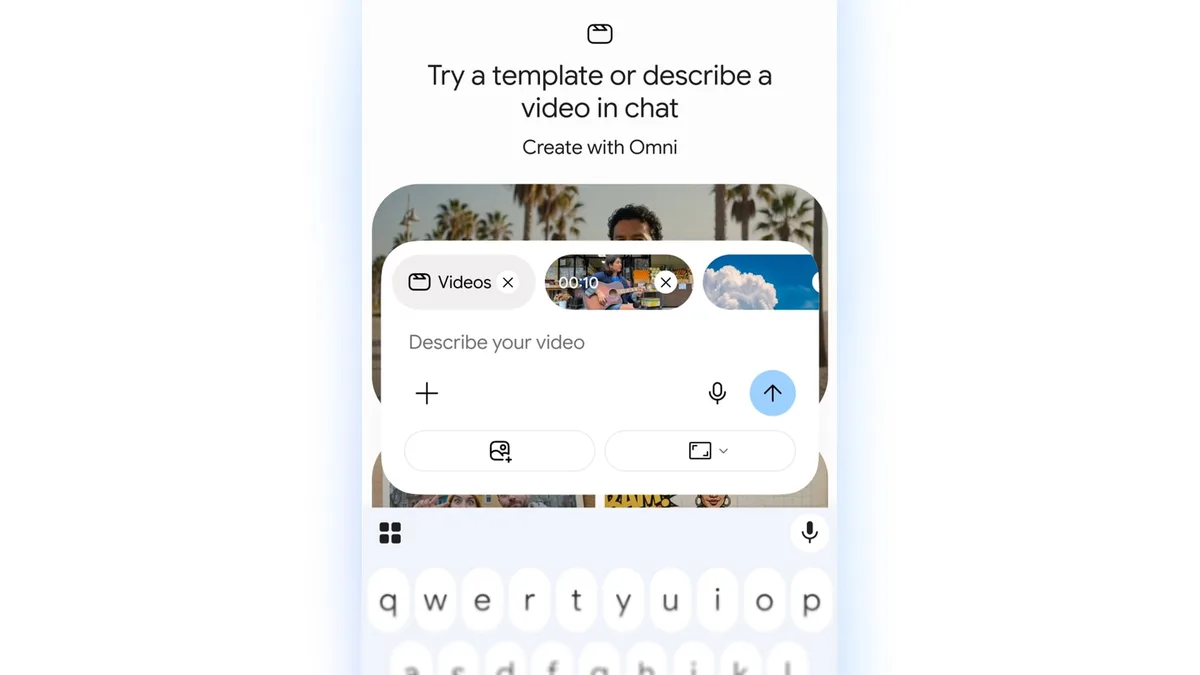
谷歌于2026年5月19日在Google I/O开发者大会上发布了Gemini Omni,一款可以通过结合文本、图像、音频和视频输入,实现视频生成和编辑的多模态人工智能模型 [1, 2, 3, 4]。该模型支持用户使用自然语言对视频进行逐步编辑,用户能修改角色、环境、摄像角度、风格乃至具体细节,提升了视频创作的灵活性和交互性 [5, 1, 2, 3]。
Gemini Omni融合了物理学、历史、科学和文化知识,提升视频的真实感和叙事能力。它能够理解重力、动能和流体力学等物理现象,从而生成更符合现实规律的视频内容 [5, 1, 2, 3]。此外,用户还能通过该模型创建与自身形象和声音相似的数字化身,支持个性化视频生成与编辑 [1, 3]。
谷歌将Gemini Omni的首批产品命名为Gemini Omni Flash,用户可通过Gemini应用程序、Google Flow以及YouTube Shorts访问。YouTube Shorts上利用Gemini Omni生成或重混的视频带有数字水印并链接回原始视频,以防止内容滥用。同时,用户还能对他人的Shorts视频进行风格重塑、插入自我画面或根据提示修改内容,增加了视频创作的互动性和开放性 [1, 6, 3]。
谷歌还同步升级了Gemini生态系统,发布了Gemini 3.5 Flash、Google AI Studio及一系列开发者工具,旨在简化生成式媒体功能的集成与应用 [4]。谷歌强调,Gemini Omni不仅是对之前Veo视频模型的升级,而是将Gemini AI智能与媒体渲染能力结合的重大进展。正如谷歌深度思维产品管理总监Nicole Brichtova所说,“这是将Gemini智能与我们的媒体模型渲染能力结合的下一步进展” [1]。
谷歌CEO Sundar Pichai表示:“Gemini Omni能‘从任何输入创造任何东西’”,凸显了该模型在多模态视频创作领域的广泛应用潜力 [1]。Gemini Omni通过自然语言指令,实现跨多轮编辑保持视频的一致性和连贯性,极大地简化了视频制作流程 [5, 2, 3]。
Gemini Omni的发布为内容创作者提供了强大的工具,能够从单一视频出发,进行无限的改造和创新。预计谷歌将继续推动该技术在谷歌平台及生态系统内的广泛部署与应用。